

Am 28. November 2019 war ich bei Interface (Unternehmen für Politikevaluation und -beratung) in Luzern eingeladen, einen Weiterbildungsworkshop zu leiten. Dieser stand unter dem Titel: Big Data in den Sozialwissenschaften.
(1) Was ist Big Data?
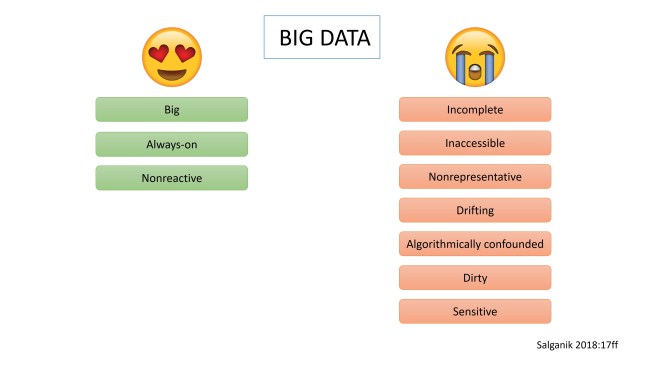
10 Charakteristika (Salganik 2018:17ff):
- Big:
Large datasets are a means to an end; they are not an end in themselves. - Always-on:
Always-on big data enables the study of unexpected events and real-time measurement. - Nonreactive:
Measurement in big data sources is much less likely to change behavior. - Incomplete:
No matter how big your big data, it probably doesn’t have the information you want. - Inaccessible:
Data held by companies and governments are difficult for researchers to access. - Nonrepresentative:
Nonrepresentative data are bad for out-of-sample generalizations, but can be quite useful for within-sample comparisons. - Drifting:
Population drift, usage drift, and system drift make it hard to use big data sources to study long-term trends. - Algorithmically confounded:
Behavior in big data systems is not natural; it is driven by the engineering goals of the systems. - Dirty:
Big data sources can be loaded with junk and spam. - Sensitive:
Some of the information that companies and governments have is sensitive.
Neue Möglichkeiten
- Re-Integration von quantitativer und qualitativer Expertise: gemeinsame Nutzbarmachung quantitativer (quantifizierte Daten, Umgang mit statistischer Software) wie qualitativer Kompetenzen (interpretative Kompetenzen, Vielfalt von Datensorten: neben Zahlen, Text, Bilder, Videos, etc.)
- Erweiterung des Methodenwissens
- Überwindung von Disziplinengrenzen und Kollaboration mit Natur- und Technikwissenschaften
Neue Stolpersteine und ungelöste Fragen
- Gefahr neo-positivistisch-technokratischer Evidenzproduktion ohne Berücksichtigung sozialer Kontexte
- ‘Kolonisierung’ der Sozial- durch Technikwissenschaften (zum Beispiel aktuelle Situation im Feld Computational Social Science) – interdisziplinäre Zusammenarbeit ist bisher eher die Ausnahme
- Dominanz von Open Data (und anderen “Open-Feldern”: Open Science, Open Government etc.) > der grosse “Datenschatz” ist heute privatisiert
- Infrastrukturen für entsprechende Forschung/Datenzugänge
- Wer ist für die ethischen Fragen zuständig?
(2) Die Rolle der Sozialwissenschaften
- ‘Domain knowledge’ natürlich 🙂
grosse Datensätze werden fast ausschliesslich in heterogenen Teams zusammengesetzt aus verschiedenen Disziplinen bearbeitet. Sozialwissenschaftliche Expertise je nach Thema sehr wichtig - Verständnis für Methoden, Vorgehens- und Denkweisen der anderen Disziplinen
- qualitativ-evaluative Expertise in den quantifizierenden Diskurs einbringen;
> kritischer Blick auf Prozesse der Datenkonstruktion – welche sozialen und soziotechnischen Prozesse haben Daten mitgeformt statt objektiv abgebildet zu werden?
Herausforderung: Methoden- und Informatikwissen tendenziell ausbauen, ohne allerdings zur reinen ‘sozialen Physik’ (Pentland) zu verkommen.
Beispiel: Der Lucerne Master in Computational Social Sciences, der seit Herbst 2019 an der Universität Luzern angeboten wird.
(3) Aktuelle Forschungsfragen
Methoden:
Methodische Fragen und Probleme in verschiedenen Disziplinen, beispielsweise empirische Sozialforschung:
- wie fehlende/mangelnde Kausalität oder Inferenz von Big Data
- neue Modi der Datenerhebung (Apps)
- «text as data» als methodische Herausforderung aufgrund der interpretativen Offenheit, die bestehen bleibt bei Verfahren computergestützter Textanalyse
Algorithmen:
In den letzten 2 bis 3 Jahren ist die Aufmerksamkeit für Algorithmen stark gestiegen, insbesondere Fairness-, Accountability- und Transparency-Aspekte werden vermehrt erforscht/thematisiert.
(4) Hands-On!
Daten
Open-Data-Repositorien:
- opendata.swiss (diverse grosse Schweizer Institutionen und Verwaltungen)
- FORS, Schweizer Kompetenzzentrum für Sozialwissenschaften
- EU-Daten-Portal
Social Media:
- Twitter via API
- Facebook, Instagram und andere bieten keine API…
Sonst im Netz:
- Google Dataset Search
- Weitere Datenbanken: https://data.opendatasoft.com/pages/home/
- Weitere Tipps: https://www.dataquest.io/blog/free-datasets-for-projects/
- Mit Scraping lässt sich vieles (fast alles?) vom Netz holen!
Werkzeuge
- R ist heute für statistische Auswertungen die gängige Programmiersprache
> R-Studio als Programmier-Umgebung
> Es gibt gute Packages für Visualisierungen der Auswertungen (ggplot2) und auch Textanalyse
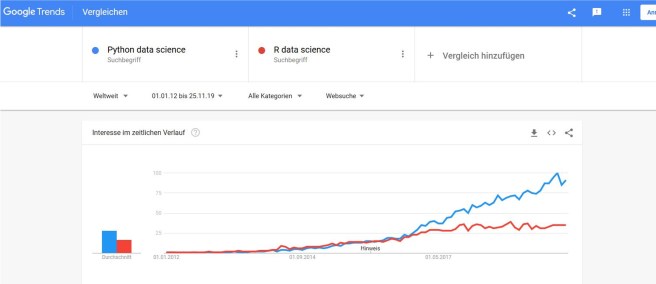
> Heute wird Statistik an der Uni mit R gelehrt und gelernt - Python ist heute unter Data Scientists die verbreitetste Programmiersprache
In einem ersten Schritt: Mitreden können in den spezifischen Programmiersprachen-Communities ist der erste und wichtigste Schritt!
Auf diesem Grundstock kann man dann für spezifische Interessen und Projekte sein Wissen vertiefen und Packages nach seinen Bedürfnissen suchen.
Wichtig zudem:
- Computational Notebook: Kommunikation über Daten-Auswertungen mit Personen, welche weniger technisches Know-How mitbringen. Beispiele:
R-Markdown, IPython, Jupyter Notebooks, ObservableHQ - Visualisierungen werden wichtiger: Wie Informationen und Zusammenhänge darstellen?
> Beispiel NYT: https://www.nytimes.com/interactive/2018/03/19/upshot/race-class-white-and-black-men.html
> Visual Vocabulary FT: https://github.com/ft-interactive/chart-doctor/blob/master/visual-vocabulary/Visual-vocabulary.pdf
Wie einsteigen?
Matt Salganik (2018): Bit by Bit. Social Science Research in the Digital Age. Princeton: Princeton University Press.
https://www.bitbybitbook.com/
Etwas theoretischer:
Noortje Marres (2017): Digital Sociology. The Reinvention of Social Research. Cambridge: Polity.
http://noortjemarres.net/index.php/books/
